How to obtain domain names from IP address
How to obtain domain names from IP address
In internet is very easy obtain the ip address asociated a domain name, but do the inverse operation is more dificult. You can use the resolution inverse of DNS but will not obtain a complete list of the sites hosted in this IP.
For example:
apolo@pegasus:~/$ ping riojasalud.es
PING riojasalud.es (195.235.64.148) 56(84) bytes of data.
apolo@pegasus:~/$ host 195.235.64.148
148.64.235.195.in-addr.arpa is an alias for 148.144.64.235.195.in-addr.arpa.
148.144.64.235.195.in-addr.arpa domain name pointer 148.red-195-235-64.customer.static.ccgg.telefonica.net.
How you can see the inverse resolution not work very well because isn’t designed for do this function.
One solution is use the search’s engine Bing. Bing have a dorck that permit search by ip. Using this dork you can view the results and determinate the domain names.
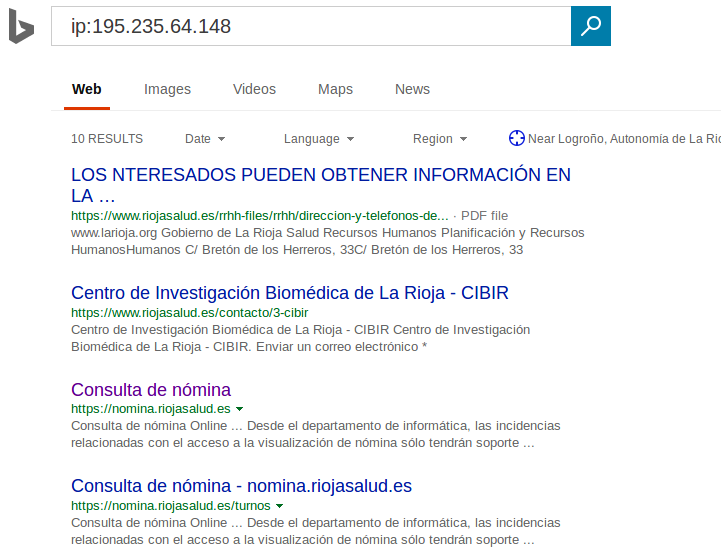
Using the Bing’s API you can make a script that do it automatily, for example this:
#!/usr/bin/env python
import requests
import json
import time
import sys
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-i', dest='ip')
parser.add_argument('-k', dest='apikey')
args=parser.parse_args()
ip = args.ip
url = "https://api.cognitive.microsoft.com/bing/v5.0/search/"
h={"Ocp-Apim-Subscription-Key": args.apikey}
c=50
o=0
validador = True
while validador:
p={'q': "ip:{0}".format(ip), 'count':c, 'offset':o}
results = requests.get(url, params=p, headers=h)
if results.status_code == 200:
datos=json.loads(results.text)
for i in datos['webPages']['value']:
if "http" in i['displayUrl'].split("/")[0]:
try:
print i['displayUrl'].split("/")[2]
except:
pass
else:
print i['displayUrl'].split("/")[0]
c+=50
o+=50
time.sleep(6)
if len(datos['webPages']['value']) != 50:
validador=False
else:
validador=False
The use is very easy, for example for the ip of riojasalud.es
apolo@pegasus:~/$ python searchdomain.py -k $your_api_key -i 195.235.64.148
www.riojasalud.es
www.riojasalud.es
nomina.riojasalud.es
nomina.riojasalud.es
Or elpais.com
apolo@pegasus:~/$ python searchdomain.py -k $your_api_key -i 91.216.63.240
elpais.com
economia.elpais.com
internacional.elpais.com
cincodias.com
politica.elpais.com
elpais.com
as.com
los40.com
as.com
tecnologia.elpais.com
internacional.elpais.com
tecnologia.elpais.com
ccaa.elpais.com
verne.elpais.com
elviajero.elpais.com
ccaa.elpais.com
resultados.as.com
resultados.as.com
economia.elpais.com
baloncesto.as.com
resultados.elpais.com
motor.as.com
futbol.as.com
cultura.elpais.com
verne.elpais.com
cultura.elpais.com
epv.elpais.com
tenis.as.com
del40al1.los40.com
cortas.elpais.com
futbol.as.com
politica.elpais.com
resultados.elpais.com
colombia.as.com
servicios.elpais.com
deportes.elpais.com
deportes.elpais.com
cadenaser.com
motor.as.com
cadenaser.com
opinion.as.com
masdeporte.as.com
ciclismo.as.com
masdeporte.as.com
ciclismo.as.com
elviajero.elpais.com
yu.los40.com
cincodias.elpais.com
Exist more techniques for do this task and the best form for do this process is collect information using all posibles techniques
Regards!